Loading...
About this Episode
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。
如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com
今天的主题是:
Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Summary
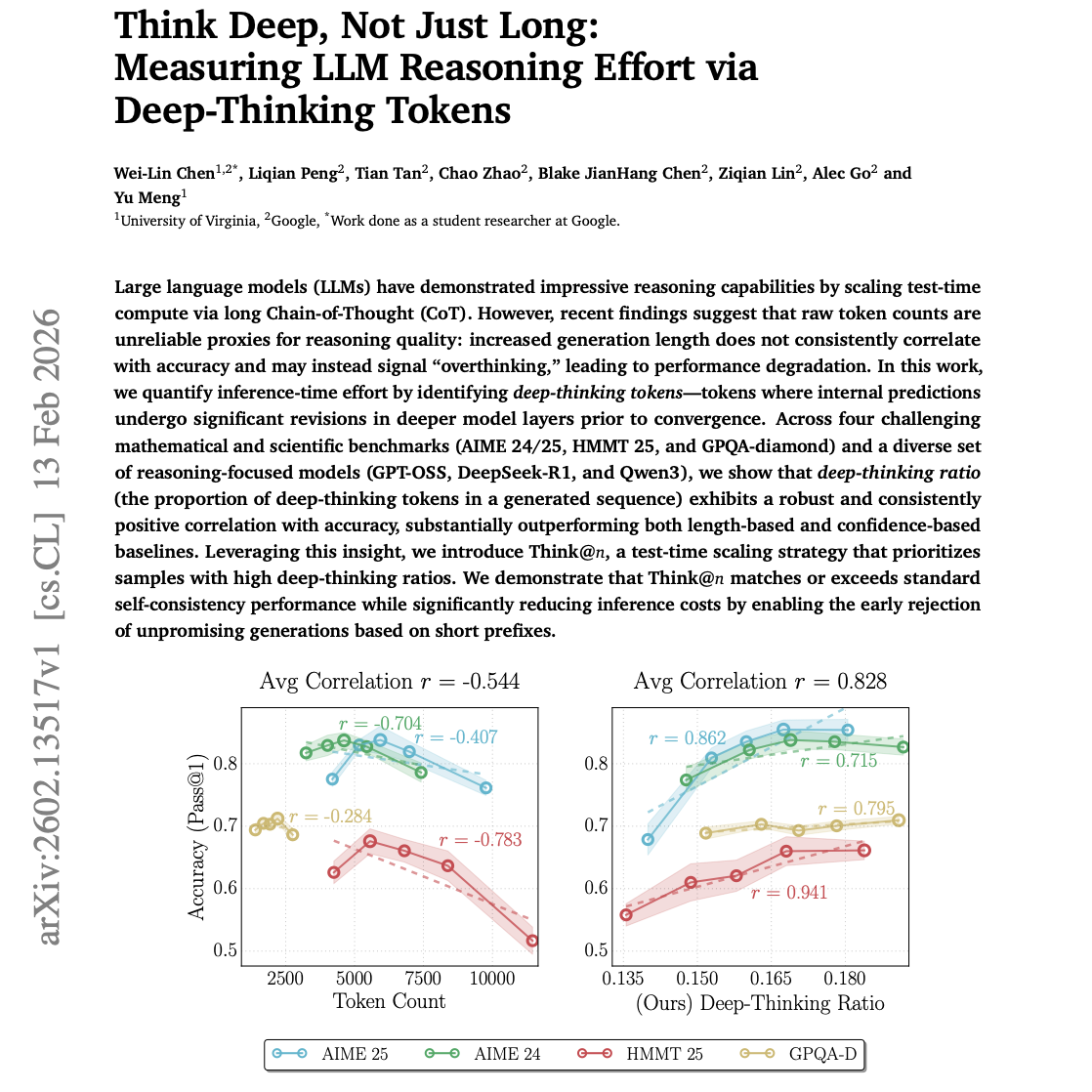
大语言模型(LLM)通过长思维链(CoT)扩展测试时计算(test-time compute),展现了令人印象深刻的推理能力。然而,近期的研究表明,原始 Token 数量并不能可靠地代表推理质量:生成长度的增加并不总是与准确率正相关,反而可能预示着“过度思考”(overthinking),导致性能下降。
在这项工作中,我们通过识别深度思考 Token(deep-thinking tokens)来量化推理时的努力程度。这些 Token 的特征是:在模型层级收敛之前,其内部预测在更深的模型层中经历了显著的修正。
我们在四个具有挑战性的数学和科学基准测试(AIME 24/25、HMMT 25 和 GPQA-diamond)以及一系列专注于推理的模型(GPT-OSS、DeepSeek-R1 和 Qwen3)上进行了实验。结果表明,深度思考占比(生成序列中深度思考 Token 的比例)与准确率之间存在稳健且持续的正相关性,其表现显著优于基于长度或基于置信度的基准指标。
基于这一洞察,我们提出了 Think@n:一种优先考虑高深度思考占比样本的测试时缩放策略。我们证明了 Think@n 在匹配或超越标准自洽性(self-consistency)性能的同时,通过根据简短前缀提前拒绝(early rejection)无望的生成内容,显著降低了推理成本。
原文链接:https://arxiv.org/abs/2602.13517
Hosts & Guests
No transcript available for this episode.



